
The Anatomy of an Outage: A Perspective for Business Leaders
Key Insights
Major IT outages and cyber events are no longer rare edge cases. They are an expected part of operating in a complex, interconnected environment. This insight focuses on how organisations respond in the moment, and more importantly, how they build long term resilience. It includes:
Why the first response to an incident must go beyond surface level root cause analysis.
How systemic weaknesses in architecture, process, and culture create the conditions for failure.
The common organisational patterns that turn small issues into full scale outages.
What effective leadership communication looks like during and after an incident.
Why resilience investment must be balanced, not driven by panic or unlimited spend.
The four types of risk leaders must evaluate when deciding how resilient is “enough”.
The cultural and operational questions every organisation should ask after an outage.
Full insight below or click here to skip to key takeaways.
Read time: 6 minutes
Cyber events and IT outages are becoming more and more common, over the past year alone, major organisations like Marks & Spencer, Jaguar Land Rover, Harrods, British Airways, Royal Mail, and even the NHS have experienced significant disruptions.
In some cases, customers were locked out of services, supply chains were halted, and operational continuity was completely compromised.
The reality is clear: every organisation, whether in financial services, retail, manufacturing, or the public sector, will at some point face an outage or cyber event. The question is not if, but when. And when it happens, the way leaders respond, and how well they have prepared, will define the organisation’s resilience and long-term health.
Drawing on my experience working with organisations in high-pressure situations, here is how I think about responding to and limiting the impact of major IT failures.
What is the immediate move when operations grind to a halt?
When an incident occurs, operational triage is the job of your IT or incident management teams. This will also include your cyber specific teams. But as a CIO or CTO, your responsibility is to ensure you have the right people in place to carry out a proper root cause analysis. That means:
Putting in reactive controls immediately to reduce the spread of the incident if it is a live actor or propagating issue.
Pinpointing the exact time the outage occurred.
Managing customers, reputation, and board expectations.
Mapping the scope of impact: are some services down, or is it total?
Tracing back to the specific change or event that triggered the incident.
This gives you the immediate, point in time cause. But most organisations make the mistake of stopping here. They identify the engineer’s mistake or the misconfigured change, patch it, and move on.
That is short sighted. To use a simple analogy: it is like discovering your car broke down because a spark plug failed but ignoring the fact you have not had an MOT or service in two years. Understanding the broader systemic weaknesses is what separates a temporary fix from long-term resilience.
The Anatomy of an Outage
Many organisations believe they are resilient. There are redundancies, backups, and fault tolerance. But when you dig deeper, you often find the “glue” holding everything together, the core infrastructure, has no redundancy at all.
This is why a single misconfigured update, a skipped step, or a small human error can cascade into a full blown outage. In cyber events, this risk is amplified: if your systems are single domain, untested, or poorly segmented, the blast radius can affect your entire operation.
From my experience, the systemic issues behind outages almost always fall into the same categories:
Architecture not mapped to business strategy: decisions are made in isolation without understanding how they align to business priorities.
Moving to solutions too quickly: organisations sometimes jump straight to products without fully defining requirements, which leads to inappropriate or unnecessary changes and increases rather than reduces risk.
Engineers promoted into architecture positions without proper training: even highly capable engineers need frameworks, guidance, and training to design holistically. Promoting someone without preparation is a recipe for blind spots, it is like using a pickaxe as a sledgehammer.
Processes and documentation gaps: no playbooks, incomplete workbooks, insufficient logging of changes. Teams end up reacting instead of executing controlled, repeatable processes.
Third-party blinkers: vendors validate their own products, but nobody checks whether the entire service integrates properly. This creates hidden weak points where failures propagate.
The common thread is clear: outages are rarely caused by a single error. They are usually the outcome of multiple systemic gaps converging at the wrong moment.
Communicating After an Incident
One of the biggest challenges after a major incident is communication. Boards, regulators, and customers do not want blame games; they want clarity, accountability, and reassurance.
The right approach sounds like this:
“Leadership is fully supporting the team through triage and investigation. We have identified the specific trigger and are now working across departments to strengthen processes, capabilities, and resilience to reduce the likelihood of recurrence.”
Notice the framing: supportive, collaborative, forward looking. No scapegoating, no vague promises, just honesty and direction.
Avoiding the “Throw Money at It” Trap
After a significant incident, the instinct is often to spend aggressively to prevent a repeat. But blindly throwing money at the problem rarely delivers efficient outcomes.
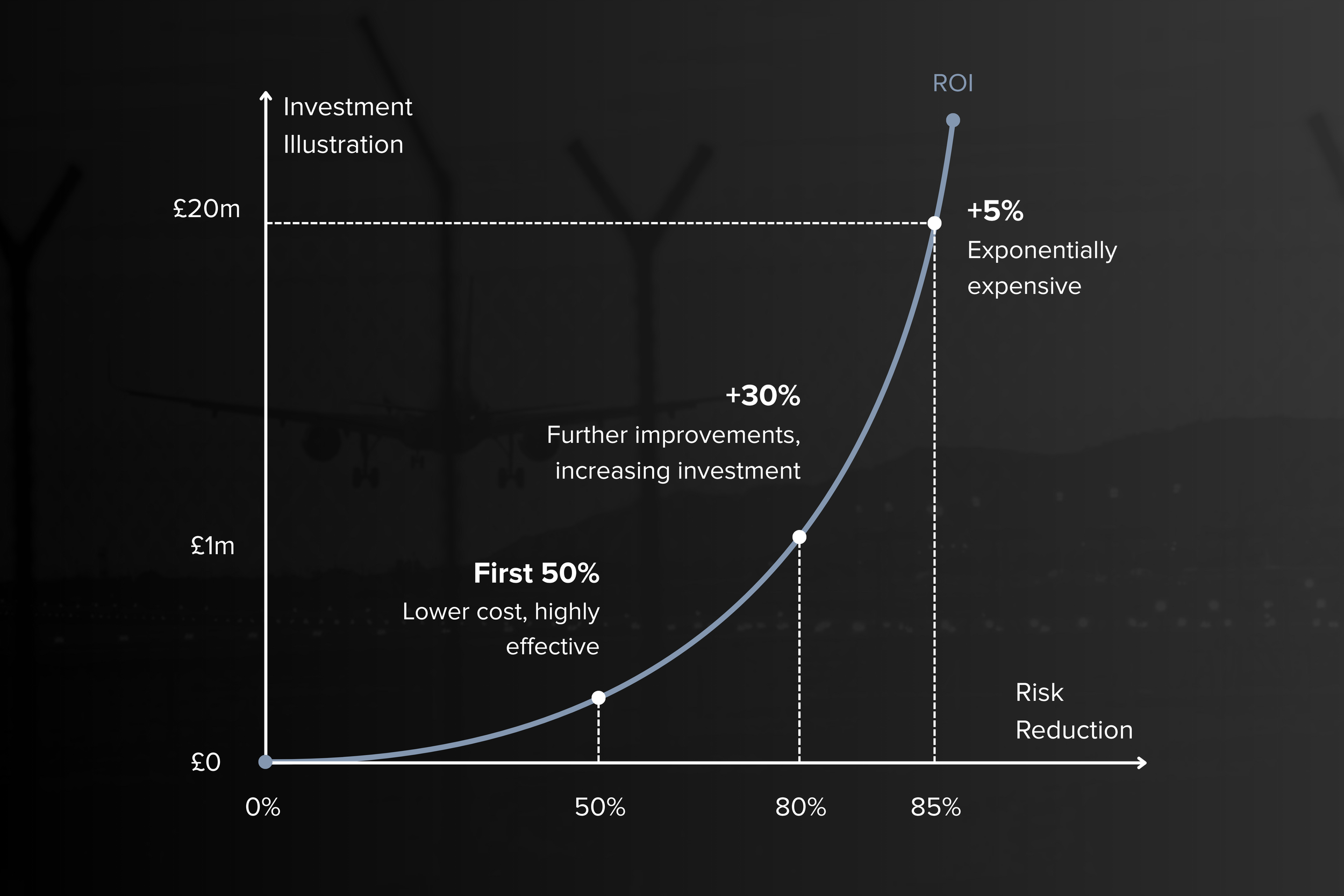
Think of investment in resilience as a curve:
The first 50% of improvements are cheap and highly effective, for example, Cyber Essentials level security measures.
The next 30% delivers further improvements, but at increasing cost.
The final 20% is exponentially expensive. You might spend £1m to get to 95% resilience, but £20m to get to 100%.
The question every leader must answer is: where do we want to be on that curve?
This requires evaluating four types of risk:
Regulatory and compliance: what is legally required? Failure to meet obligations can shut down the business.
Operational: which services must remain operational at all costs?
Reputational: how much damage would an incident do to trust, credibility, and brand value? Some failures are not your fault, but perception is everything.
People: how far can you push your teams before burnout, attrition, or disengagement undermine your resilience? Many organisations rely on heroic effort during incidents, which is not sustainable.
True resilience is not just about systems, it is also about people, processes, and culture.
Post-Mortem: Five Questions Every Business Should Ask
Once systems are back up, patching the immediate fault is only part of the work. A thorough post-mortem should include these five questions:
Are we blinkered in our architecture? Designs must be validated not only technically but also against actual business requirements and strategic goals.
What does my team actually need? Have risks been raised for months without response? Are teams overloaded with a “just get it done” mentality?
Are our processes fit for purpose and even understood? Are changes properly logged? Is documentation up to date? Do threat assessments identify weak points?
What is our culture? Can engineers challenge decisions without fear? Are people encouraged to speak up? Without this, hidden problems will inevitably escalate. Your engineers are your experts and you need to listen and discuss.
Final thoughts:
Cyber events and IT outages are not rare, they are a recurring, escalating threat. The trigger may be a single error or a targeted attack, but the enablers are almost always systemic: gaps in architecture, culture, process, and strategy.
Fixing these issues requires more than patching the immediate fault. It requires a fundamental mindset shift, from reactive firefighting to proactive resilience.
Resilience is built not just in technology, but in the combination of people, processes, leadership mindset, and solid architectural values with a balanced view of risk versus reward. Those who recognise that risk can never be eliminated, and who spend wisely on the right challenges without overwhelming the business or creating unsustainable debt, will be the ones who survive and thrive when the next major incident inevitably strikes.
Key Takeaways for Businesses
• Go beyond immediate fixes by conducting root cause analysis that addresses not just the trigger, but the wider systemic weaknesses across architecture, processes, and decision making
• Ensure architecture is aligned to business strategy, with clear understanding of critical services, dependencies, and the potential blast radius of failure
• Strengthen governance around change, documentation, and incident management so teams can operate through controlled, repeatable processes rather than reactive firefighting
• Invest in capability development, particularly when moving engineers into architecture positions, to avoid gaps in holistic design thinking
• Validate end to end service resilience, not just individual components, ensuring third party solutions integrate effectively without creating hidden points of failure
• Adopt clear, transparent communication during incidents, focusing on accountability, reassurance, and forward looking actions rather than blame
• Take a balanced approach to resilience investment, understanding where diminishing returns begin and aligning spend to regulatory, operational, reputational, and people risks
• Embed a culture where teams can challenge decisions, raise risks early, and avoid reliance on unsustainable “heroic effort” during incidents
By addressing the systemic causes behind outages, not just the symptoms, organisations can move from reactive recovery to proactive resilience, strengthening both operational stability and long term business confidence.
Cyber events and IT outages are inevitable, but their impact doesn’t have to be. Platform Smart partners with organisations to strengthen people, processes, and technology, helping you respond effectively when it matters most and build long-term resilience. Whether you need expert support for critical incidents or a strategic approach to capability development, we create solutions that fit your organisation.
If you want to strengthen your resilience and stay ahead of evolving cyber and operational threats, get in touch today.